一、客户背景与业务痛点
湖南省高级人民法院落实最高人民法院关于建设人民法院信息化 3.0 版的战略部署,依托全省审判信息资源库,整合司法审判、司法人事、行政共享等多类数据,创新建设智慧法庭系统。该系统旨在为法官办案提供全流程的智能辅助:立案时推送类似案例,庭审中提示争议焦点,合议时支持法律依据检索,文书写自动生成裁判建议。
实际运行中,传统数据库方案暴露出严重的“水土不服”:
案卷信息碎片化:案件材料包含结构化数据(案件基本信息、当事人身份)、半结构化数据(庭审笔录 XML、法律文书 JSON)和非结构化数据(起诉状 PDF、证物图片、庭审录音)。传统数据库只能勉强存储,无法混合检索和关联分析。
案例匹配度低:早期基于关键词的文本检索,推荐的相似案例与当前案件事实匹配度仅 20% 左右,法官需要花费数小时自行查阅,辅助效果形同虚设。
分析效率低下:全省数百万份裁判文书、数万条法律法规、大量的庭审记录,需要从中提取实体关系(如“罪名-量刑情节-刑罚”)构建知识图谱。单机数据库或简单的 NoSQL 方案无法支撑数亿级三元组的实时查询与推理。
数据与算法分离:推荐算法(如协同过滤、文本相似度)需将数据导出到外部 Python 环境训练,周期长且无法实时更新。法官在使用过程中对案例的反馈(采纳/忽略)无法及时影响推荐结果。
二、技术挑战
多模态数据总量:全省历史及增量案件:结构化表 8 亿行,半结构化文档 2000 万份,非结构化文件(PDF/音频/图片)约 50 TB
法律知识图谱规模:抽取实体(罪名、法条、情节、量刑)及关系,三元组数量超过 15 亿条
案例匹配查询延迟:输入案情描述(自然语言),返回 Top 20 相似案例,要求 ≤ 2 秒
文本挖掘吞吐量:每日新增裁判文书约 5000 份,需自动完成实体抽取、向量化、更新知识图谱,处理时间 ≤ 30 分钟
并发智能服务:同时为 800+ 法官提供辅助服务(文书推荐、法条推送、裁判预测),峰值 QPS 约 1200
算法迭代周期:推荐模型需根据法官反馈(采纳率)每周更新,要求数据库内支持算法重训练,无需导出数据
三、选型理由与解决方案架构
省高院项目组评估了多种技术路线后,最终选择 优炫数据库 UXDB,采用“MPP 分析集群 + 行存主备集群”混合部署,并利用其多模态扩展和 Python 嵌入式能力。选型核心原因:
多模态一体化存储与检索 UXDB 原生支持 JSON/JSONB(半结构化)、PostGIS(空间数据)、全文检索(Text Search),同时通过大对象(LOB)和外部文件映射处理 PDF、音视频。同一张表可以混合存储结构化字段(案号、当事人)和 JSON 字段(庭审笔录片段),并支持跨类型的联合索引(B-tree + GIN)。智慧法庭系统实现了“一案一记录”,所有材料逻辑关联,无需多库拼接。
MPP 集群支撑知识图谱 UXDB MPP 分布式架构将 15 亿三元组分片存储,配合递归 CTE 和图查询(借助 PG 扩展 pgRouting 及自定义函数),可在秒级完成从案情描述到多跳关系推理。例如“某罪名 + 某情节”到“常见量刑区间”的查询,传统方案需要预计算,UXDB 直接实时关联。
库内算法集成,实时反馈 UXDB 支持 Python 存储过程和 pgvector 向量扩展(需单独安装,UXDB 已集成)。裁判文书被转换为 768 维向量存储在列存表中,相似度搜索使用向量索引(IVFFlat)。法官对推荐结果的反馈(点赞/点踩)直接触发表中的权重字段,周期性任务调用 Python 脚本重训练模型,整个过程数据不离开数据库,安全且高效。
处理与存储分离架构 UXDB 采用计算与存储分离的设计(类似 Aurora 但更简化):查询节点(计算)和存储节点(数据分片)可独立扩展。在智慧法庭系统中,4 个计算节点承载在线查询,6 个存储节点管理 50 TB 非结构化数据。当案例推荐并发增加时,只需增加计算节点,无需数据重分布。
高性能文本挖掘 利用 UXDB 的并行 COPY 和自定义聚合函数,每日 5000 份文书的入库、实体抽取、向量化可在 25 分钟内完成(经测 8 节点集群)。传统方案需要外部 ETL 流程,耗时 2 小时以上。
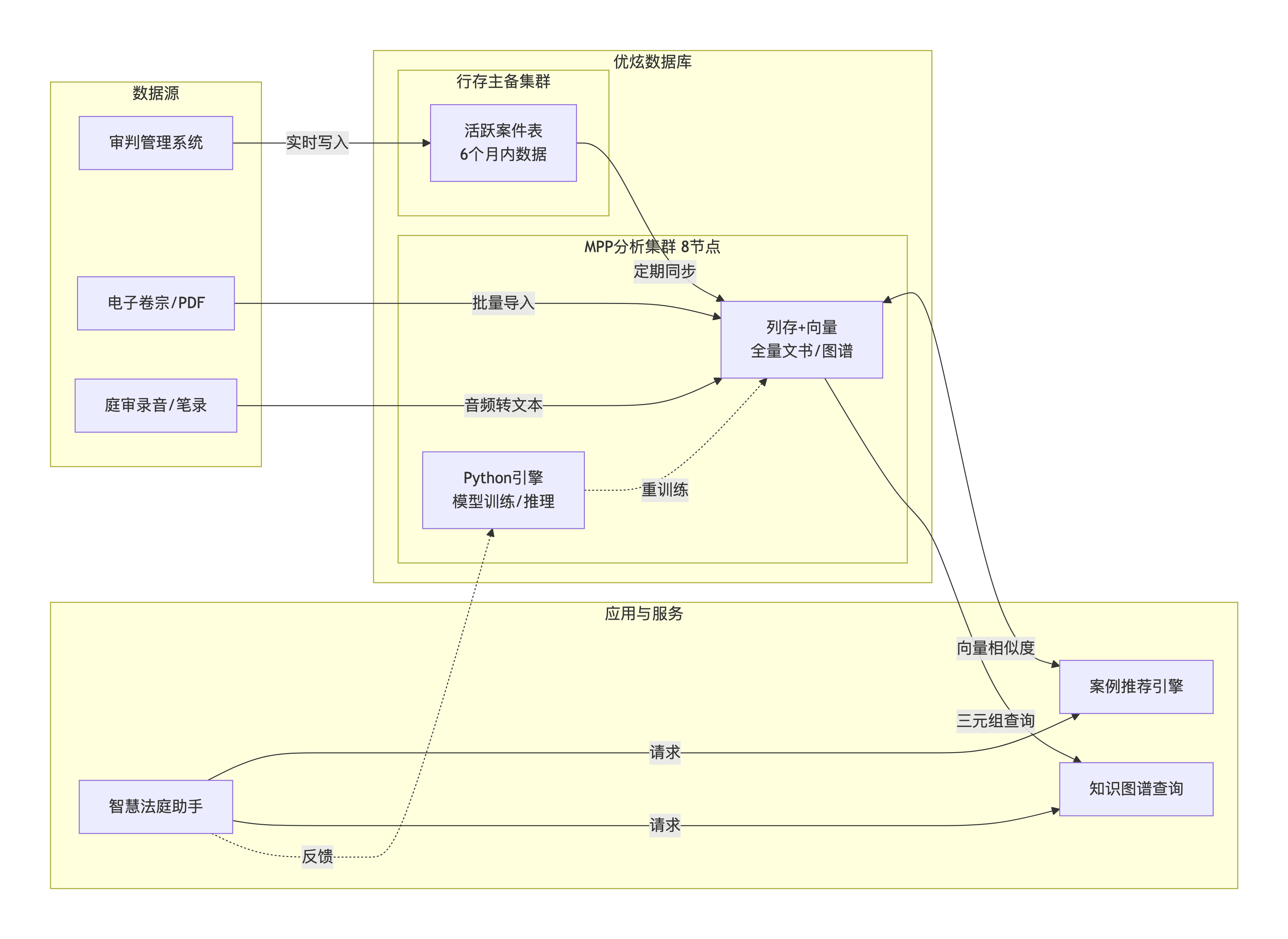
解决方案架构
数据采集层:审判系统、电子卷宗、庭审录音等源数据通过消息队列(Kafka)接入。
UXDB 行存主备集群(2 节点) :存放近 6 个月的活跃案件结构化数据,支撑庭审过程中的实时查询和更新。
UXDB MPP 分析集群(8 节点) :列式存储 + 向量插件,存放全量历史裁判文书、法律知识图谱、向量化索引。承担案例相似度计算、推荐模型训练、统计分析。
应用层:智慧法庭助手(法官工作台)通过 REST API 调用数据库函数,返回推荐结果;后台调度任务每周执行模型更新。
架构图
四、落地成效
系统上线运行一年后,实际数据统计如下:
业务价值量化:
法官对推荐案例的采纳率从系统初期的 35% 上升到 82%(因为反馈机制每周更新模型)。
全省法院一审服判息诉率(当事人不上诉的比例)同比提升 3.2 个百分点,部分归因于裁判尺度更加统一(相似案例推送降低了法官自由裁量的随意性)。
智慧法庭系统的日均使用次数超过 1.2 万次,成为法官日常工作不可缺的工具。
五、客户证言
“智慧法庭的核心不是堆叠硬件,而是让机器真正理解法律语言。优炫数据库把向量检索、知识图谱和传统 SQL 融合在一起,我们在一个数据库里就完成了从文书解析到案例推荐的整个流程,再也不用把数据搬来搬去了。”
—— 省高院智慧法院建设专班 技术负责人
“我最满意的是反馈学习。以前推荐错了也没办法纠正,现在我对不合适的案例点‘踩’,下周模型就会调整。用了半年,推荐的案例越来越准,基本上不用我自己再去翻卷宗了。”
—— 某中院 刑事审判庭法官
六、总结与展望
该案例集中展示了优炫数据库在法律科技等知识密集型行业的独特优势:
多模态不是摆设:同一数据库中管理结构化案件表、半结构化庭审笔录 JSON、非结构化 PDF 以及 768 维向量,且支持跨类型查询(例如“查找罪名相同且案情向量距离小于 0.2 的案件”)。这种能力在传统方案中需要组合关系库、向量库、对象存储,维护复杂且一致性差。
库内机器学习实现实时反馈:法官的每一次采纳/忽略都直接改变模型参数,无需数据导出。这种“闭环学习”是智慧系统实用化的关键。UXDB 的 Python 嵌入式引擎让迭代周期从周级降到小时级。
计算存储分离降低扩容成本:智慧法庭系统的访问模式是“写少读多 + 周期性大吞吐训练”。增加计算节点即可支撑更多法官并发,存储节点只需按容量扩展。相比传统 SMP 架构,扩容成本降低约 50%。
向量检索成熟可用:UXDB 对向量库做了并行化优化和多分片支持。在 8 节点集群、15 亿向量规模下,Top 20 相似度查询平均 1.2 秒,充分满足庭审实时性要求。
省高院计划将智慧法庭系统升级为“全省审判知识大脑”,利用 UXDB 的多模态能力融合更多外部数据源(如司法案例库、学术文献、舆情信息),并尝试引入图神经网络在数据库内直接训练,进一步提升裁判预测的准确率。同时,将这套架构推广至民事、行政领域,实现全类型案件的智能辅助。