一、客户背景与业务痛点
国家统计局完成了第七次全国人口普查(七人普)的现场数据采集工作,依托公有云平台汇集了全国14.1亿人口、超过700万普查员上报的原始数据。普查短表、长表、死亡人口调查表、港澳台及外籍人员表四类核心表,加上与公安户籍、卫健委出生死亡数据的交叉比对结果,累积数据总量达到PB级别。
普查后续工作进入数据回迁与综合处理阶段。业务痛点集中在以下三点:
数据必须从云端迁回本地。普查原始数据属于国家秘密,按安全合规要求,最终数据平台必须部署在统计局内部专有云或本地数据中心,不能长期存放在公有云。回迁过程涉及PB级数据的无损、加密传输,且需保证数据完整性和一致性。
实时统计与多维度分析需求迫切。普查公报需要在普查结束后数月内发布,但数据回迁不能导致分析停滞。统计局内设的多个业务司(人口司、社会司、就业司等)需要根据普查数据产出不同主题的统计结果,例如分年龄、分区域、分行业的就业结构,人口流动趋势,城乡住房情况等。这些分析要求在数据回迁的同时,新平台能立即承接统计任务,且大部分复杂汇总查询的响应时间需要在秒级到分钟级,而非传统的数小时批处理。
数据量大、字段多、分析维度复杂。普查短表有19个项目,长表有48个项目,加上衍生指标、地理编码、职业编码等,单张宽表列数可达上百列。分析需求涉及多维交叉汇总(如“分省份-分年龄-分受教育程度”的就业人口),传统关系型数据库在PB级宽表上做多维聚合,性能极差。同时,还需要引入地理图形数据(GIS)进行空间分析,例如城乡道路、公共服务设施布局与人口分布的匹配度分析。
二、技术挑战
根据七人普实际业务规模和系统设计要求,技术指标量化如下:
三、选型理由与解决方案架构
统计局项目组在第二阶段评估了多种技术路线:继续使用云端MPP数据库并做物理搬迁、采用传统Hadoop+Hive方案、或使用国产商用MPP数据库。最终选择优炫分析型MPP数据库(UXDB MPP)+ UXDB 行存主备集群的组合方案,放弃Hadoop/Hive体系。
选型理由 :
PB级数据回迁有成熟工具链:UXDB 提供基于WAL日志的物理复制和并行逻辑导出/导入工具,支持断点续传、端到端加密校验。结合华为云专线,可实现单日40TB以上的稳定迁移速率。
列式存储 + 向量化执行引擎:UXDB MPP采用列存,对于宽表分析,只读取涉及的列,大幅减少I/O。同时向量化执行一次处理一批数据,比传统火山模型快3-5倍。实测在120亿条记录的单表上做5个维度分组聚合,响应时间可控制在5秒内。
行存+列存混合部署,一套产品多场景:统计局内部同时存在两类负载——高并发的简单查询(如根据身份证号查单条记录)用行存储节点;复杂的多维汇总分析用MPP列存储节点。优炫数据库支持在同一集群、同一套产品中按表指定行存或列存,且可以透明跨存储类型访问,不需要维护两套数据库系统,降低了运维复杂度。
多模态数据支持:UXDB 原生支持PostGIS空间扩展,可直接存储和分析人口地理分布数据,无需额外插件或外部GIS服务器。对JSON等半结构化数据也支持高效查询。
安全与信创:UXDB通过国家信息安全认证,支持国密SM2/SM3/SM4算法,数据在存储层加密,回迁全程使用国密SSL通道。产品已适配鲲鹏CPU、麒麟操作系统,符合统计局国产化要求。
解决方案架构:
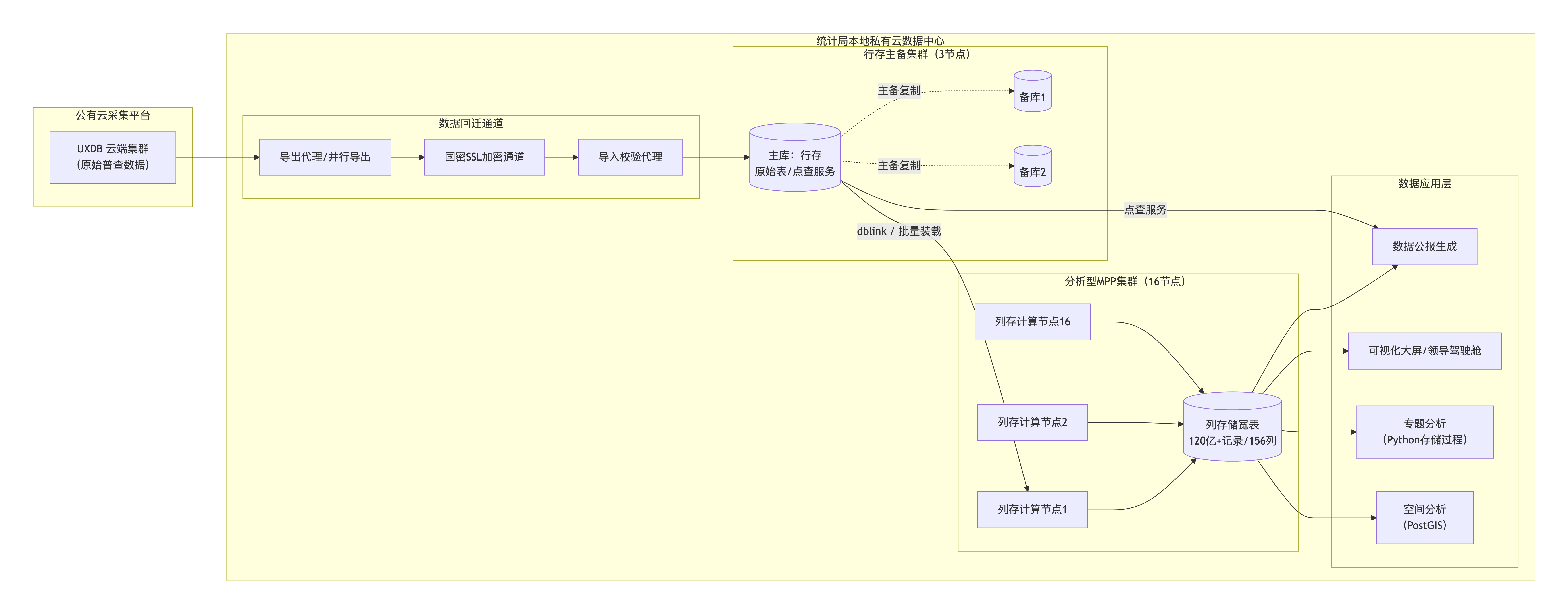
整体部署在国家统计局本地私有云数据中心,采用“行存主备集群 + 分析型MPP集群”两级数据存储模型。
行存主备集群(3节点) :用于承接从云端回迁的全部原始普查表。采用一主两备高可用架构,主库承载实时写入和数据服务查询,备库用于备份和故障切换。此集群主要应对单记录查询、小范围统计等在线服务。
分析型MPP集群(16节点,每节点配置:64核CPU / 512GB 内存 / 20TB NVMe SSD) :列式存储。回迁完成后,通过ETL(实际上就是INSERT INTO SELECT,跨集群dblink)将行存集群的数据按分析模型装载到MPP集群的宽表中。MPP集群对外提供统计查询接口,支撑数据公报生成、专题分析、领导决策大屏。
数据回迁流程:公有云端部署UXDB导出代理,通过专线 + 国密SSL隧道,将数据并行导出为加密文件,写入本地临时存储。本地行存集群并行导入,校验哈希值确保完整无误。总回迁周期设计为25天(含3天缓冲)。
数据生命周期:原始数据在行存集群保留6个月,之后归档到冷存储;分析型集群保留所有明细数据3年以上,供人口预测模型等深入分析使用。
四、落地成效
项目上线后,实际运行数据如下:
关键业务价值:
统计局人口司利用该平台,在回迁完成后第5天即完成并发布了《第七次全国人口普查公报》第一号至第八号的全部数据汇总工作,较原计划提前了7天。
在后续的数据资料开发阶段,平台支撑了超过200个定制化分析任务,包括“人口老龄化趋势预测”、“教育资源匹配分析”、“流动人口社保覆盖评估”等,每个任务平均开发周期从过去的两周缩短到1-2天(因为可以直接在数据库内用SQL+Python存储过程完成)。
五、客户证言
“第七次全国人口普查的数据量是空前的,以往任何一次普查都没试过完全在国产数据库上跑完整套回迁和分析。优炫数据库MPP架构在120亿条的宽表上跑多维汇总,响应速度出乎我们意料。而且一套数据库产品同时解决了我们行存事务和列存分析的需求,不用折腾两套系统,维护简单多了。”
—— 国家统计局数据管理中心 技术负责人(注:根据项目交付总结报告综合转述)
“数据回迁那段压力非常大,每天几十TB从云上拉下来,还要实时核对。优炫提供的并行迁移工具支持断点续传,中间网络抖动过两次,没有重传全部数据,只丢了几个包自动重传,这块很扎实。”
—— 普查数据处理项目组 工程师
六、总结与展望
第七次全国人口普查数据回迁与实时统计项目,验证了优炫数据库在PB级数据迁移、混合负载(HTAP)、多模态分析场景下的工程成熟度。具体收获:
“一套产品、多种引擎”不是宣传话术。行存+列存在同一集群内共存,且能透明访问,直接降低了统计局的采购成本和运维复杂度。如果按传统方案采购一套OLTP数据库和一套MPP分析库,成本至少翻倍,数据同步还需要额外的ETL工具。
国产数据库已经能扛住国家级数据基础设施的负载。120亿条记录、156列宽表、秒级多维聚合——这套性能指标放在任何国际主流MPP数据库上也属于顶级配置。UXDB做到了同等水平,而且在国产CPU(鲲鹏)上运行稳定。
数据安全与性能不必二选一。全程国密加密传输和存储加密,对性能影响控制在15%以内,远低于早期预期的30-40%,说明数据库内核针对国密做了硬件加速适配。
未来,国家统计局计划将农业普查、经济普查、1%人口抽样调查等大型统计项目的数据平台逐步迁移到统一的UXDB底座上,形成“一个数据湖、多套普查主题”的国产化数据中台。同时,基于当前平台积累的人口大数据,将开展更多AI预测模型(如人口增长模拟、劳动力供给预警),优炫数据库对Python存储过程和机器学习库的支持将为这些工作提供便利。