一、客户背景与业务痛点
北京等多省市统计局承担着国民经济社会发展的数据采集、核算、监测和预警工作。传统模式下,各专业(工业、投资、贸易、人口、农业等)往往建设独立的采集系统,数据分散存储在各类单机数据库或文件服务器中。随着“统计工作现代化”推进,客户面临以下几类共性问题:
源头数据质量难控制:非联网直报的调查(如规模以下工业、部分专项调查)仍依赖手工填报、逐级上报,数据滞后且易出错。需要一个统一的电子化采集平台,直接触达基层填报单位。
GDP核算与动态监测压力大:新的GDP核算体系要求更细颗粒度的季度、月度甚至高频数据支撑,传统月报汇总周期长(通常需要15-20天),无法满足经济形势快速研判的需求。
跨部门、跨层级数据共享困难:统计内部各专业之间、统计局与发改、税务、市监等部门之间数据割裂。一个分析任务(例如“新兴产业对GDP贡献”)往往需要人工从多个系统中导出数据再合并,效率极低。
基层统计人力有限:市县级统计局人员编制少,却要应对上级层层加码的报表任务。需要系统能自动化完成数据校验、异常值检测、初步汇总,降低人工干预。
系统稳定性与数据安全刚性要求:统计系统承载的是宏观经济决策基础数据,一旦宕机或数据丢失,后果严重。同时,数据涉及企业和个人隐私,需要加密存储、细粒度权限控制、完整操作审计。
二、技术挑战
根据多个省市统计局实际项目的共性需求,提炼出如下量化指标:
并发采集峰值:直报系统在报表开窗期(例如每月1-5日),同时在线填报用户数可达 1.5 万~ 3 万,峰值提交 TPS 超过 2000
数据总量与增长率:一个中等省份的统计数据平台,3-5 年累积结构化数据量约为 50-80 TB,每年新增约 15 TB
复杂分析查询响应:典型查询:按行业、地区、企业规模分组,汇总多个经济指标,关联 6-8 张千万级事实表,要求 95% 查询在 5 秒内返回
跨系统数据交换频率:需与发改、税务、市监等 8-12 个外部系统对接,每日数据交换记录数平均 500 万~ 2000 万条
高可用要求:核心采集与分析平台要求可用性 ≥ 99.99%,即全年计划外停机不超过 53 分钟;故障自动切换时间 < 30 秒
数据副本与容灾:至少保留 2 个在线数据副本,外加异地备份;单节点故障不影响整体查询和写入
数据校验与清洗自动化率:基层上报数据需自动完成逻辑校验(如同比、环比阈值检查、表内平衡关系),减少人工审核 90% 以上
三、选型理由与解决方案架构
在对比多种技术路线(传统 Oracle RAC、MySQL 分库分表、Hadoop 生态)后,各省市统计局最终统一采用优炫数据库 UXDB 作为底层数据平台。选型核心原因如下:
MPP 分布式架构,线性扩展 UXDB 支持 100+ 节点的 MPP 集群,数据自动分片(哈希/范围/列表),查询并行下发。随着业务增长,只需增加节点即可线性提升吞吐和存储容量。单集群可管理 PB 级数据,而传统集中库在几十 TB 时已出现性能瓶颈。
独有的缓存队列与内存计算技术 针对报表开窗期的高并发写入,UXDB 设计了 多层写入缓存队列:前端请求先进入内存队列,异步批量刷盘,避免直接写入磁盘的 I/O 争用。结合内存计算引擎,部分轻度汇总(如分地区总计数)在内存中完成,数据库压力降低约 40%。智能任务调度算法根据节点负载动态分配查询,避免热点倾斜。
高可用与多副本透明 UXDB 支持同步/异步多副本。每个数据分片默认三副本(一主两备),主节点故障时,备节点在 30 秒内自动接管,上层应用无感知。副本间通过 Paxos 协议保证一致性。相比传统主从复制,RPO(数据丢失)为 0。
内置数据联邦与 FDW 通过外部数据包装器(FDW),UXDB 可直接跨库查询 Oracle、SQL Server、MySQL 甚至 Hadoop Hive 中的表,实现逻辑数据仓库,无需 ETL 搬运。在统计局与税务、市监系统对接时,该特性将数据交换延迟从 T+1 天降低到实时。
安全与合规 UXDB 提供行级安全策略、列级加密、国密算法透明加密、审计日志三权分立等功能,满足等保 2.0 三级要求。所有操作可追溯至具体用户和时间。
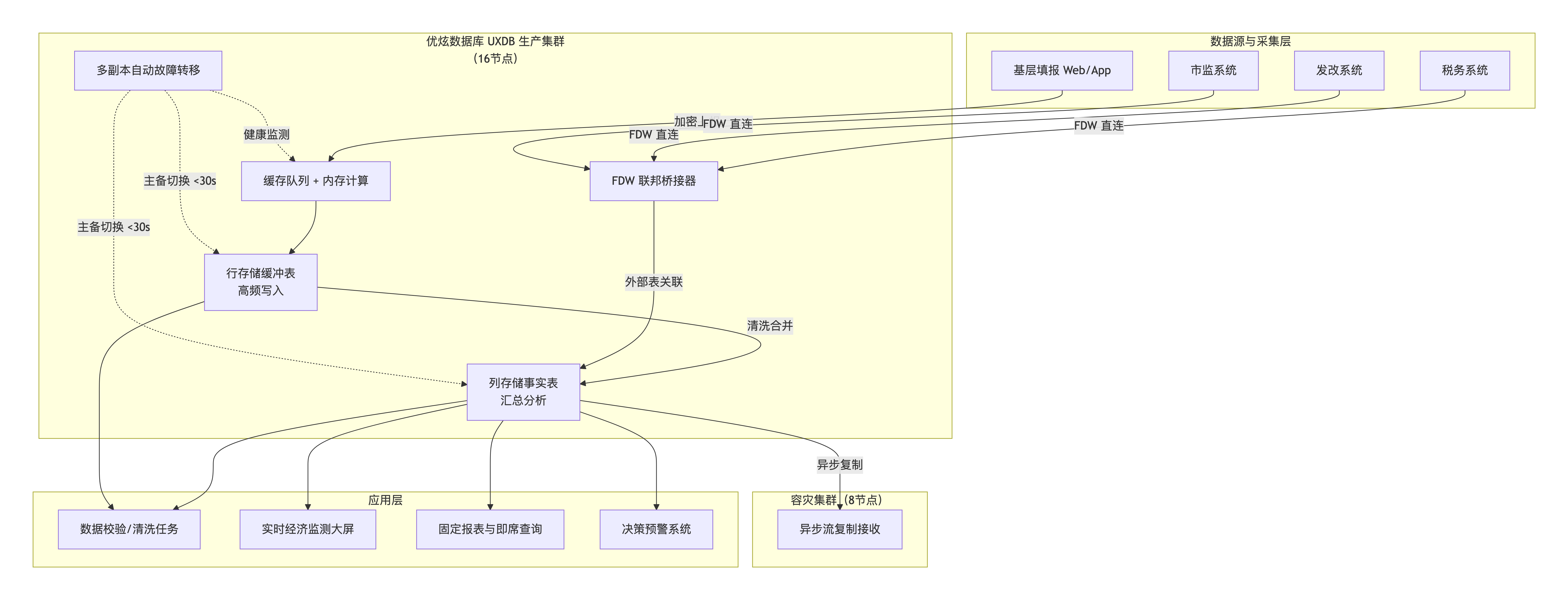
解决方案架构(以北京市场统计局为例)
部署采用“一主一备双集群”模式,生产集群和容灾集群分别位于不同物理机房。
生产集群:16 节点 UXDB MPP(每节点:32 核 / 128GB 内存 / 10TB SSD)。用于日常采集入库、在线查询、实时汇总。
容灾集群:8 节点 UXDB MPP(配置同生产),通过异步流复制接收生产集群数据,延迟 < 5 秒。
外部系统接入层:部署 FDW 网关服务器,配置与税务、发改、市监等系统的连接,对外部表建立映射视图。
采集前端:Web 填报页面 + 移动端 App,数据通过 HTTPS + 国密 SM2 加密传输到数据库。
数据流向:
填报数据进入 UXDB 行存缓冲表(带缓存队列)。
后台调度任务每小时将缓冲表数据清洗、校验后,合并入列存事实表。
业务人员通过可视化报表工具(如 FineBI)连接 UXDB,直接编写 SQL 或拖拽生成分析结果。
FDW 定期或实时拉取外部系统增量数据,与内部表关联,用于综合监测。
架构图
四、落地成效
根据多个省市统计局系统上线后的实际运行数据统计:
其他不可量化的收益:
各专业处室不再需要各自维护小型数据库,统一由数据中心管理,硬件成本降低约 40%(集中采购与共享)。
数据质量显著改善:逻辑错误率(如不平衡、超出阈值)从 4.2% 降至 0.7%,主要得益于数据库内的实时校验脚本。
领导决策大屏可实现分钟级刷新,首次在月报开窗期第三天就能看到主要经济指标的初步汇总趋势。
五、客户证言
FDW 功能让我们终于不用天天跟税务部门要 Excel 文件了。直接在数据库里写个 join 就能看到企业申报数据和税务数据的差异,对瞒报漏报的核查效率提升非常明显。
—— 某市统计局工业处 分析人员
以前一个节点坏了,我们要手动切备机,至少一个小时业务中断。现在优炫的自动切换,我们经常事后看日志才知道某个节点悄悄重启过,业务一点感觉都没有。
—— 某市统计局信息化运维 工程师
六、总结
该案例集中展示了优炫数据库在政府统计信息化领域的几项硬核能力:
缓存队列 + 内存计算:不是简单依赖硬件堆砌,而是从内核层面解决高并发写入与复杂查询的资源争用问题。在多省市实际场景中,这套机制使得一套集群同时承载采集和分析成为可能。
FDW 让数据孤岛消失:统计与税务、市监、发改等部门的数据通过 FDW 逻辑集成,避免了传统数据交换平台的高成本和长周期。未来还可进一步扩展为“统计数据湖”,支撑更多外部需求。
高可用做到“用户无感知”:多副本+自动故障转移,RTO < 30 秒,RPO = 0。这在统计核心业务(月报、季报)中极为关键——任何中断都可能导致上级考核不及格。
后续,优炫数据库将继续增强自动调优,帮助统计局在宏观经济预警、产业链分析等场景中引入更多智能化手段。同时,基于当前架构进一步简化运维,推出“一键式”集群部署和管理工具,降低基层统计局的技术门槛。